Published
Why ElevenLabs Scribe is the best transcription model
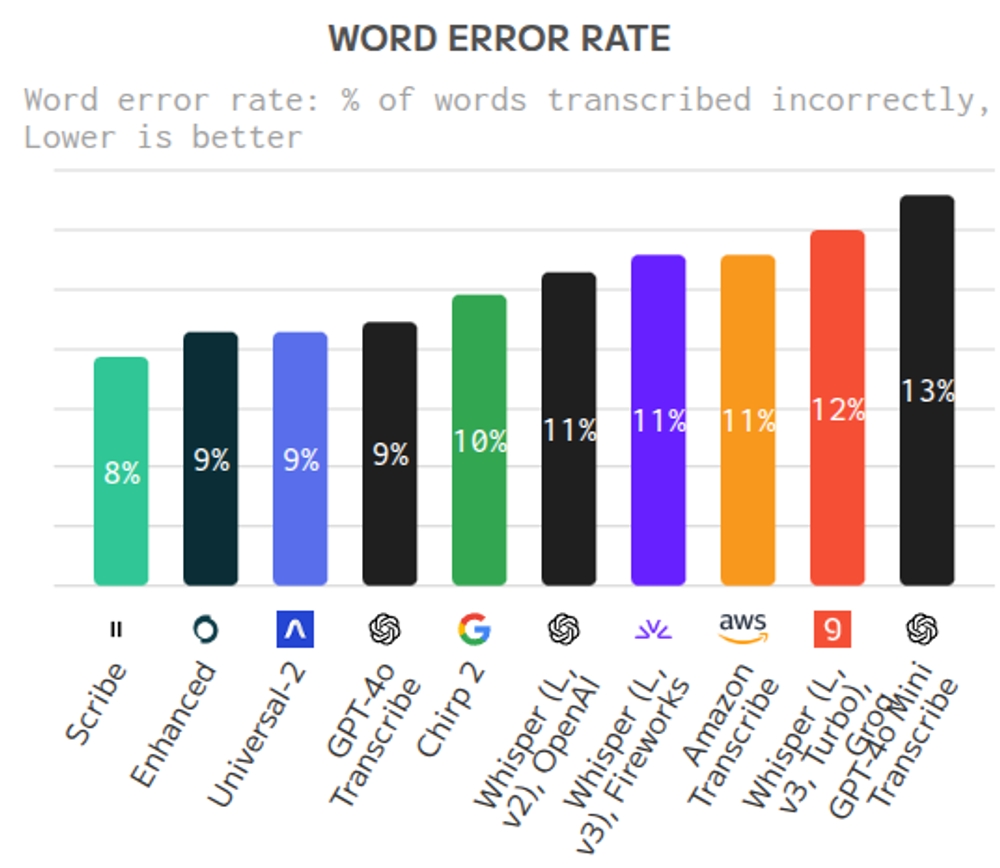
Elevenlabs is known for their industry leading text-to-speech models that allows making audio from text in a variety of voices and languages. Their bid at also providing a model for going the other way, getting the text from an audio file, has been anticipated for some time. The release of Scribe has been a success with better accuracy than all competing models, including Whisper from OpenAI and all its sub-variants.
It is unknown exactly what technology Elevenlabs uses behind the scenes for their model. It could be an improved version of Whisper in combination with some advanced audio preprocessing. This is likely as Scribe, just like Whisper, supports about a 100 languages, which is more than most alternative models out there. Unlike Whisper, Scribe optionally integrates diarization which identifies which speaker says which sentences with high accuracy. The model from Elevenlabs also supports other “audio events” such as laughter, applause, background music, etc. Finally, Scribe claims to be better at handling irregular speech such as stuttering and mumbling, which is very common in real scenarios for people using transcription professionally.
Teksta.no has performed a small test to see if the claims made are realistic, and it seems that they are. By using the word-error-rate tool, you can get data and visualize how accurate a trancription is when you have an answer to compare it to.
Elevenlabs also provides API-access to their models, so that other companies can use their state of the art models in their own applications. Teksta.no has integrated Scribe for our customers so that we can provide the most accurate transcriptions in addition to all the other tools for processing, chatting with and downloading the text.
Try Scribe at Elevenlabs or try it at Teksta.no to see for yourself.
Try Teksta.no today
Get the boring job done by AI and focus on the creative and giving parts.